Wavefrontで学ぶHorizontal Pod Autoscaler Part-2
この文章は、Wavefrontで学ぶHorizontal Pod Autoscaler シリーズの第二回目です。
シリーズ
第一回 : 概要編
第二回 : Wavefront情報からスケールする ← いまここ
第三回 : サーバーレスもどきを実装する
始めに
概要にも記載したよう、この記事では、Wavefrontのメトリクスをもとに、HPAを実装する方法を紹介します。
今回はまずシンプルにCPUベースでのHPAを実装します。
前提知識
前提知識として、HPAとしてKuberenetesの利用できるAPIとしては3つあります。
metrics.k8s.io: Coreとよばれるメトリクスである、マニュアルにあるよう、CPUとMemoryの使用率を報告します。実際の収集方法はmetrics-serverもしくは Heapster経由で取得します。なお、それらはKubernetesのデフォルトで動いているわけではなく、別途起動しないといけないものです。custom.metrics.k8s.io: 上とは別に外部データソースからメトリクスを収集してメトリクスに反映するものです。ここに一部実装可能なものが紹介されています。CNCF的にはPrometheusが推奨されています。external.metrics.k8s.io: これも外部データソースからメトリクスですが、さらに自由度の高い定義ができるようになっています。
このうち、Wavefrontでは、2と3の方法をサポートしています。 2で使えるメトリクス一覧は以下の定義されています。
https://github.com/wavefrontHQ/wavefront-kubernetes-adapter/blob/master/docs/metrics.md
これが実際のどのWavefrontのメトリクスとマッピングされるかはあとで、触れます。 3の方法では、Annotationを使い好きなメトリクスをマッピングさせることもできます。
https://github.com/wavefrontHQ/wavefront-kubernetes-adapter/blob/master/docs/metrics.md
準備編
さて検証を始める前に以下が必要です。
- WavefrontのアカウントとAPIキー
- Kubernetes環境
- Helm(v3がおすすめ) cli
なお、Wavefrontのアカウントないよ、という場合ですが、Trialの申し込みをお勧めします。 もし、それも面倒な場合、非常に多くの制約をもちますが、サインアップ不要のFreemiumアカウントもあるにはあります。
現状WavafrontのFreemiumアカウントはSpring Boot経由でないと、作成ができないようになっています。最低限、ここで紹介したようにHelloWorldアプリを作成してください。作成すると~/.wavefront_freemiumにAPIキーが含まれます。
インストール
まずは、Wavefrontのコンポーネントをインストールします。 インストールするのは、以下の2つです。
- Wavefront Collector
- Wavefront HPA Adaptor
どちらでも使うので、以下のmyvalues.yamlを用意します。
XXXXには取得したWavefrontのアカウントとAPIキーを指定します。またClusterNameは判別しやすい任意の名前をつけてください。
1clusterName: mhoshi-test
2
3wavefront:
4 url: https://XXXXX.wavefront.com
5 token: XXXXXXXXXXXXXXX
さらに、HelmのRepositoryをダウンロードします。
1helm repo add wavefront https://wavefronthq.github.io/helm/
2helm repo update
Wavefront Collectorのインストール
以下の手順でインストールします。
1kubectl create namespace wavefront
2helm install -f myvalues.yaml wavefront wavefront/wavefront --namespace wavefront
Wavefront HPA Adapterのインストール
以下の手順でインストールします。
1kubectl create namespace wavefront-adapter
2helm install -f myvalues.yaml wavefront-adapter wavefront/wavefront-hpa-adapter --namespace wavefront-adapter
以上でインストールの完了です。
CPU情報でスケールしてみる
では、HPAを早速ためしてみます。 まず作業用のネームスペースを作成します。
1kubectl create ns hpa
なんでもいいのでKubernetesのDeploymentを作成します。 筆者の場合は手っ取り早く以下で作ります。
1kubectl create deployment --image=nginx hpa-pods -n hpa
次に、HPAの定義を作ります。
1
2cat <<EOF | kubectl apply -n hpa -f -
3apiVersion: autoscaling/v2beta1
4kind: HorizontalPodAutoscaler
5metadata:
6 name: example-hpa-custom-metrics
7spec:
8 minReplicas: 1
9 maxReplicas: 5
10 metrics:
11 - type: Pods
12 pods:
13 metricName: cpu.usage_rate
14 targetAverageValue: 300m
15 scaleTargetRef:
16 apiVersion: apps/v1
17 kind: Deployment
18 name: hpa-pods
19EOF
これは、最小1、最大5Podまでを定義したHPAです。
そして、targetAverageValue: 300mにあるよう、300millisecondのCPU使用率に落ち着くことを期待しています。
HPAができたことを確認します。なお、直後はTARGETSがunknownになっているかもしれないですが、これはメトリクスがまだWavefrontに届いていない場合で、すこしまてば、値が取得されます。
1kubectl get hpa -n hpa
2NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
3example-hpa-custom-metrics Deployment/hpa-pods <unknown>/300m 1 5 0 8s
しばらくすると、TARGETSに値が入るはずです。
1kubectl get hpa -n hpa
2NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
3example-hpa-custom-metrics Deployment/hpa-pods 0/300m 1 5 1 6m20s
CPU負荷をあげていきます。 手っ取り早い方法がContainerに入って、無限ループをつくってしまう方法です。
1kubectl exec -it `kubectl get pods -l app=hpa-pods -n hpa -o name` -n hpa bash
Containerログイン後、以下のコマンドを実行します。以下のコマンドは何もしない無限ループを1つ作ります。理論的には、このコマンドによって1つのvCPU使用率を100%にします。
1while true ; do : ; done &
WavefrontのUIを開きます。 Metrics Viewerを開いて、以下の式を入力します。ClusterNameはそれぞれ指定したものを記載してください。
1ts("kubernetes.pod.cpu.usage_rate", pod_name="hpa-*" and namespace_name="hpa")
これは、namepsace名hpaのpod名hpa-*の全てのCPU使用率を算出しています。
すると以下のようにCPU使用率があがっていることがわかります。
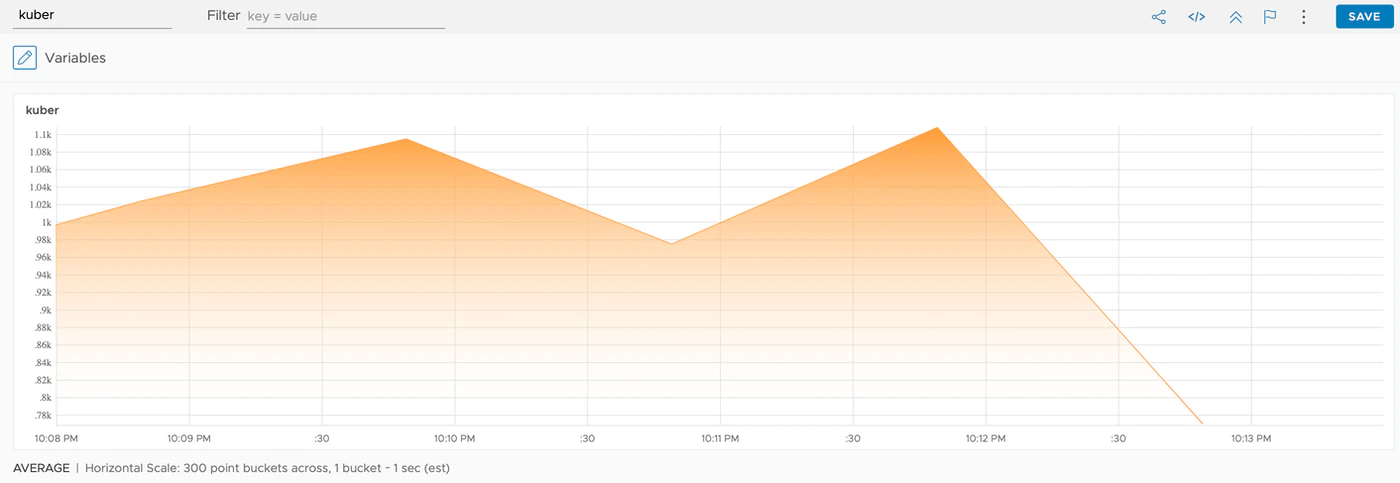
現在設定上はCPU使用率300mを超えた場合で、スケリーングを開始するようにしています。 しばらく放置すると、pod数が5に変動します。
1% kubectl get hpa -n hpa
2NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
3example-hpa-custom-metrics Deployment/hpa-pods 219200m/300m 1 5 5 19m
4% kubectl get po -n hpa
5NAME READY STATUS RESTARTS AGE
6hpa-pods-8d86f4dc5-2xn52 1/1 Running 0 8m46s
7hpa-pods-8d86f4dc5-7wnpw 1/1 Running 0 8m46s
8hpa-pods-8d86f4dc5-qbdn9 1/1 Running 0 7m12s
9hpa-pods-8d86f4dc5-r55hb 1/1 Running 0 8m46s
10hpa-pods-8d86f4dc5-wgc8g 1/1 Running 0 20m
また、CPUをぶん回したPodを止めるには以下を実行します。
1kubectl delete po hpa-pods-8d86f4dc5-wgc8g -n hpa
しばらくすると、Podがまた1で落ち着きます。
1kubectl get hpa -n hpa
2NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
3example-hpa-custom-metrics Deployment/hpa-pods 0/300m 1 5 1 35m
どうやってメトリクスは計算されている?
これについては、コードがみるのが早いです。 まず、WavefrontへのQueryを担っているのが以下の部分です。
この中でCodeのコメントアウト行にもコメントされていますが、HPAの定義をもとに以下に変換されます。
1
2 // if Prefix=kubernetes, metric='cpu.usage_rate', resType='pod', namespace='default' and names=['pod1', 'pod2']
3 // ts(kubernetes.pod.cpu.usage_rate, (pod_name="pod1" or pod_name="pod2") and (namespace_name="default"))
4 query := fmt.Sprintf("ts(%s.%s.%s%s)", t.prefix, resType, metric, filters)
つまり、HPAを以下のように定義した場合、
1
2spec:
3 ...
4 metrics:
5 - type: Pods
6 pods:
7 metricName: cpu.usage_rate
8 targetAverageValue: 300m
Wavefrontへは<prefix>.<type>.<metricName>のメトリクスを探しにいきます。
この場合
<prefix>は起動オプションでkubernetesがデフォルト<type>はHPAの定義のtype: Podsからpodに変換<metricName>はHPA定義のmetricName: cpu.usage_rateからcpu.usage_rate
つまり、kubernetes.pod.cpu.usage_rateを参照し、pod名やNamespaceを絞り込んでいくようになっています。
より標準の実装方法は、こちらにも詳しく記載されています。
まとめ
- Wavefrontでは、
custom.metrics.k8s.ioとexternal.metrics.k8s.ioをつかってHPAができる custom.metrics.k8s.ioで使える一覧はhttps://github.com/wavefrontHQ/wavefront-kubernetes-adapter/blob/master/docs/metrics.mdにあるcustom.metrics.k8s.ioでは、定義してHPAの情報を解釈してWavefrontへのメトリクスに変換して問い合わせる
この回では、Wavefrontの統計にやってくるCPU情報をもとにHPAを実装しました。 次回の「サーバーレスもどきを実装する」ではより突飛なメトリクスを元にHPAを実装してみます。